The Transformer Architecture
The Transformer Architecture
Transformer is an attention-based model that increases training speed. Parallelization is what makes the Transformer unique. Many models are built on this foundation. Researchers at Google and the University of Toronto developed Transformers in 2017 originally for translation. The three main concepts behind Transformers are:
1. Positional Encodings: In language processing, the order of words matters. The Transformer model takes all the words in the input sequence — an English sentence — and appends a number to each word to denote its order.
2. Attention: Depending on their impact on target sequence generation, individual words in the input sequence are weighed in the attention mechanism.
3. Self-Attention: Language tasks will be more manageable if a neural network learns a better internal representation of language is the concept behind self-attention. Compared to recurrent layers, self-attention layers connect all positions with an equal number of sequentially executed operations.
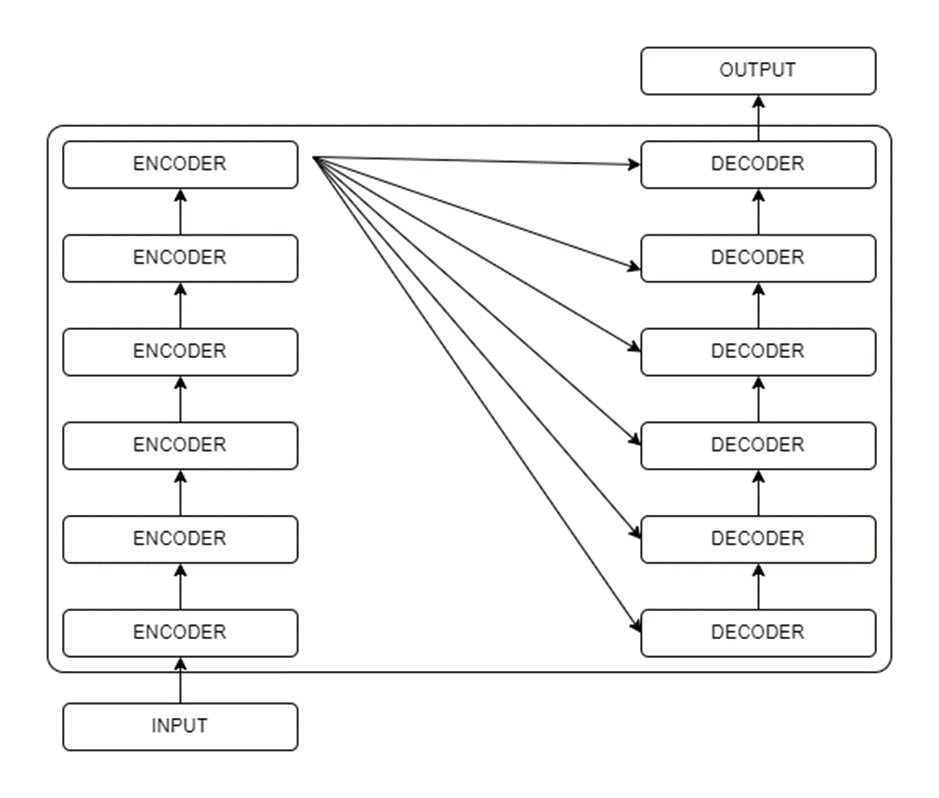
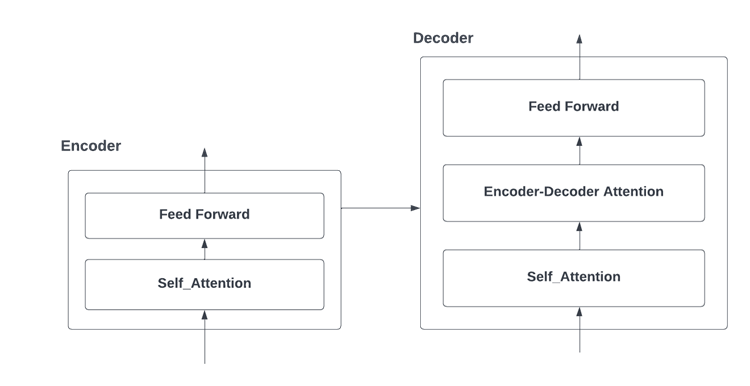
The transformer architecture contains encoding and decoding components. The encoding component contains a stack of encoders and the decoding component contains a stack of decoders. Structure-wise, all encoders are similar. First, the encoder’s inputs pass through a self-attention layer, which allows it to look for other words within the input sentence while it encodes a specific word. Self-attentional layer outputs are fed to a feed-forward neural network
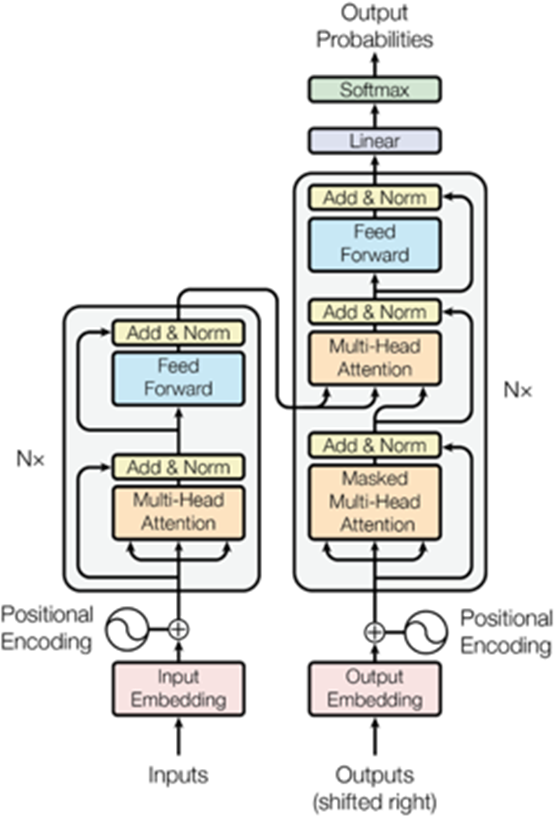
Each position uses the same feed-forward network independently. Decoder has an additional Encoder-Decoder attention layer that aids the decoder in focusing on relevant parts of the input sentence.
In every NLP application, each input text is converted into a vector using an embedding algorithm. This embedding only occurs in the encoder at the bottom. Every encoder receives a list of 512-sized vectors as the common abstraction. For the bottom most encoder, it is the word embedding and for other encoders, it is the output of the previous encoder. The size of this list is based on the longest sentences in the training set. Afterword embedding, the word in each position flows through both encoder layers through its own path in the encoder. These paths in the self-attention layer are interdependent. But in the feed-forward layer, these paths are independent and executed in parallel. Top encoder outputs are converted into a set of attention vectors. (Attention vectors are created from the top encoder output). To focus on appropriate inputs, each decoder uses these in its “encoder-decoder attention” layer. A decoder’s self-attention layer operates differently from an encoder’s. Self-attention layer in the decoder can only pay attention to earlier positions in the output sequence (Alammar, 2020). In order to accomplish this, future positions are masked in the decoder self-attention layer. The decoder stack produces a vector of floats.
The final linear layer consists of a simple fully connected neural network that produces a huge vector, called a logits vector, based on the output from the stack of decoders. These vectors are then converted into probabilities by the softmax layer.
Transformer models fall into three categories.
1. Sequence-to-sequence Transformer models: Also known as Encoder-decoder models. It uses both the encoder and decoder parts of the transformer architecture. The pretraining of these models is a bit more complex. Sequence-to-sequence models are ideal for tasks involving generating new sentences based on a given input, such as summarizing, translating, or answering generative questions.
2. Auto-regressive Transformer models: In decoder-only models, only the decoder of a Transformer is used. That is why it is often called the decoder model. Attention layers can only access words positioned before a given word at each stage. Text generation is the best application for these models.
3. Auto-encoding Transformer models: These use only the encoders associated with a transformer model. The attention layers have access to all of the words from the original sentence at each stage. Bi-directional attention is often referred to as a characteristic of these models. Ideally, encoder-only models should be used for extractive question answering, sentence classification and named entity recognition.
References
Alammar, J. (2020) The illustrated transformer, The Illustrated Transformer — Jay Alammar — Visualizing machine learning one concept at a time. Available at: https://jalammar.github.io/illustrated-transformer (Accessed: July 21, 2022).
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin,I., 2017. Attention Is All You Need. arXiv preprint. 1706.03762



Comments
Post a Comment